JVM内存管理相关整理
1. Java虚拟机运行时的数据区
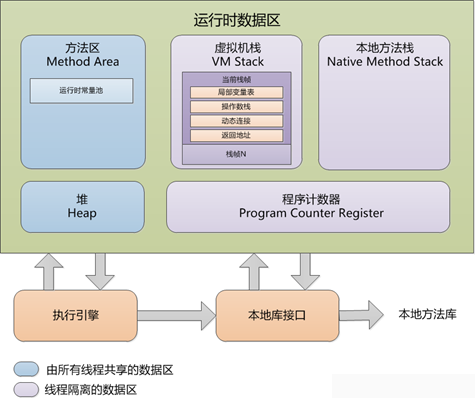
进一步看看各个区域的内容:

程序计数器(program counter register)
是一块较小的内存空间,是当前线程所执行的字节码的行号指示器。如果线程正在执行一个java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果是Naive方法,则计数器为空;这个区域不会出现OutOfMemoryError异常。java虚拟机多线程是使用线程轮流切换并分配处理执行时间的方式来实现的,在任何一个确定的时刻,一个处理器都只会执行一条线程中的指令。为了线程切换后能够恢复到正确的执行位置,每条线程都需要一套独立的线程计数器,这些计数器之间相互独立,独立存储,这个内存区域为“线程私有”。
虚拟机栈(VM stack)
java虚拟机栈也是线程私有,与线程的生命周期一致,在执行每个方法都会创建一个Stack Frame。每一个方法从开始执行到结束,对应一个Stack Frame在虚拟机值栈中从入栈和出栈的过程。如果线程请求的栈深度大于虚拟机所允许的深度,就会出现StackOverFlowException。如果允许动态扩展,在扩展的过程中,如果无法申请到足够的内存,则会抛出OutOfMemoryException异常。
本地方法栈(native method stack)
和java虚拟机栈的作用类似,不同点在本地方法栈主要是为虚拟机使用到的Native方法提供服务,本地方法栈也会抛出StackOverFlowException和OutOfMemoryException异常。
堆(heap)
堆是java虚拟机中内存中最大的一块,被所有线程共享的一块内存区域,在虚拟机创建时创建。作用就是存放对象实例,所有的对象的实例都需要在这里分配内存。几乎所有的对象实例和对象数组都需要在堆上分配。是java虚拟机内存回收的管理的重要区域,因此也被称为“GC”堆,可以被分为:新生代和老年代;Eden空间、From Survivor空间、To Survivor空间。如果堆中没有内存完成实例分配,并且堆也无法扩展时,则抛出OutOfMemoryException异常。
方法区(method area)
方法区和java堆一样,是各个线程共享的内存区域,用于存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译的代码等数据。通常被开发人员成为“永久带”。这个区域的内存回收的目标就是针对常亮池的回收和对类型的卸载,也是较为难处理的部分。
2. 常用内存参数调节
-Xms
初始堆大小,默认为物理内存的1/64(<1GB);
默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;
-Xmx
最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制;
-Xmn
新生代的内存空间大小,注意:此处的大小是(eden + 2 survivor space)。与jmap -heap中显示的New gen是不同的。整个堆大小=新生代大小 + 老生代大小 + 永久代大小;
在保证堆大小不变的情况下,增大新生代后,将会减小老生代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8;
-XX:SurvivorRatio
新生代中Eden区域与Survivor区域的容量比值,默认值为8。两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10;
-Xss
每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。应根据应用的线程所需内存大小进行适当调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。一般小的应用, 如果栈不是很深, 应该是128k够用的,大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:-Xss is translated in a VM flag named ThreadStackSize
一般设置这个值就可以了;
-XX:PermSize
设置永久代(perm gen)初始值。默认值为物理内存的1/64;
-XX:MaxPermSize
设置持久代最大值。物理内存的1/4;
3. 内存分配方式
- 堆上分配
- 栈上分配
- 堆外分配(
DirectByteBuffer或直接使用Unsafe.allocateMemory,但不推荐这种方式)
4. 内存使用监控方法
- 系统程序运行时可通过
jstat –gcutil来查看堆中各个内存区域的变化以及GC的工作状态; - 启动时可添加
-XX:+PrintGCDetails –Xloggc:<file>输出到日志文件来查看GC的状况; jmap –heap可用于查看各个内存空间的大小;- 断代法可用GC汇总?????
5. GC

新生代GC
-
串行GC (Serial Copying)
client模式下默认GC方式,也可通过-XX:+UseSerialGC来强制指定;默认情况下eden、s0、s1的大小通过-XX:SurvivorRatio来控制,默认为8,含义 为eden:s0的比例,启动后可通过jmap –heap [pid]来查看。
默认情况下,仅在TLAB或eden上分配,只有两种情况下会在老生代分配:
(1) 需要分配的内存大小超过eden space大小;
(2) 在配置了PretenureSizeThreshold的情况下,对象大小大于此值。 默认情况下,触发Minor GC时,之前Minor GC晋级到old的平均大小 < 老生代的剩余空间 <eden+from Survivor的使用空间。当HandlePromotionFailure为true,则仅触发minor gc;如为false,则触发full GC。
默认情况下,新生代对象晋升到老生代的规则:
(1) 经历多次minor gc仍存活的对象,可通过以下参数来控制:以MaxTenuringThreshold值为准,默认为15;
(2)to space放不下的,直接放入老生代; - 并行GC (ParNew)
CMS GC时默认采用,也可采用-XX:+UseParNewGC强制指定;垃圾回收的时候采用多线程的方式。 - 并行回收GC(Parallel Scavenge)
server模式下默认的GC方式,也可采用-XX:+UseParallelGC强制指定;eden、s0、s1的大小可通过-XX:SurvivorRatio来控制,但默认情况下以-XX:InitialSurivivorRatio为准,此值默认为8,代表的为新生代大小:s0,这点要特别注意。
默认情况下,当TLAB、eden上分配都失败时,判断需要分配的内存大小是否 >=eden space的一半大小,如是就直接在老生代上分配;
默认情况下的垃圾回收规则:
(1) 在回收前PS GC会先检测之前每次PS GC时,晋升到老生代的平均大小是否大于老生代的剩余空间,如大于则直接触发full GC;
(2) 在回收后,也会按照上面的规则进行检测。
默认情况下的新生代对象晋升到老生代的规则:
(1) 经历多次minor gc仍存活的对象,可通过以下参数来控制:AlwaysTenure,默认false,表示只要minor GC时存活,就晋升到老生代;NeverTenure,默认false,表示永不晋升到老生代;上面两个都没设置的情冴下,如UseAdaptiveSizePolicy,启动时以InitialTenuringThreshold值作为存活次数的阈值,在每次ps gc后会动态调整,如不使用UseAdaptiveSizePolicy,则以MaxTenuringThreshold为准;
(2) to space放不下的,直接放入老生代。在回收后,如UseAdaptiveSizePolicy,PS GC会根据运行状态动态调整eden、to以及TenuringThreshold的大小。如果不希望动态调整可设置-XX:-UseAdaptiveSizePolicy。如希望跟踪每次的变化情况,可在启动参数上增加:PrintAdaptiveSizePolicy。
老年代GC
-
串行GC(Serial Copying)
client方式下默认GC方式,可通过-XX:+UseSerialGC强制指定。 触发机制汇总:
(1)old gen空间不足;
(2)perm gen空间不足;
(3)minor gc时的悲观策略;
(4)minor GC后在eden上分配内存仍然失败;
(5) 执行heap dump时;
(6) 外部调用System.gc,可通过-XX:+DisableExplicitGC来禁止; -
并行回收GC(Parallel Scavenge)
server模式下默认GC方式,可通过-XX:+UseParallelGC强制指定;并行的线程数为当cpu core<=8 ? cpu core : 3+(cpu core*5)/8或通过-XX:ParallelGCThreads=x来强制指定。如ScavengeBeforeFullGC为true(默认值),则先执行minor GC; - 并行Compacting
可通过-XX:+UseParallelOldGC强制指定; - 并发CMS
可通过-XX:+UseConcMarkSweepGC来强制指定。并发的线程数默认为:(并行GC线程数+3)/4,也可通过ParallelCMSThreads指定。 触发机制:
(1) 当老生代空间的使用到达一定比率时触发; Hotspot V 1.6中默认为65%,可通过PrintCMSInitiationStatistics(此参数在V 1.5中不能用)来查看这个值到底是多少;可通过CMSInitiatingOccupancyFraction来强制指定,默认值并不是赋值在了这个值上,是根据如下公式计算出来的:((100 - MinHeapFreeRatio) +(double)(CMSTriggerRatio * MinHeapFreeRatio) / 100.0)/ 100.0; 其中,MinHeapFreeRatio默认值是40,CMSTriggerRatio默认值是80;
(2) 当perm gen采用CMS收集且空间使用到一定比率时触发;
perm gen采用CMS收集需设置:-XX:+CMSClassUnloadingEnabled, Hotspot V 1.6中默认为65%;可通过CMSInitiatingPermOccupancyFraction来强制指定,同样,它是根据如下公式计算出来的((100 - MinHeapFreeRatio) +(double)(CMSTriggerPermRatio* MinHeapFreeRatio) / 100.0)/ 100.0; 其中,MinHeapFreeRatio是40,CMSTriggerPermRatio默认值是80。
(3) Hotspot根据成本计算决定是否需要执行CMS GC;可通过-XX:+UseCMSInitiatingOccupancyOnly来去掉这个动态执行的策略。
(4) 外部调用了System.gc,且设置了ExplicitGCInvokesConcurrent;需要注意,在hotspot 6中,在这种情况下如应用同时使用了NIO,可能会出现bug。
6. GC组合
默认组合
可选组合


7. GC监测
如下方式可以查看gc状态:
jstat –gcutil [pid] [intervel] [count]-verbose:gc(可以辅助输出一些详细的GC信息);-XX:+PrintGCDetails(输出GC详细信息);-XX:+PrintGCApplicationStoppedTime(输出GC造成应用暂停的时间);-Xloggc:[file](将GC信息输出到单独的文件中,建议都加上,这个消耗不大,而且对查问题和调优有很大的帮助。gc的日志拿下来后可使用GCLogViewer或gchisto进行分析);- 图形化的情况下可直接用
jvisualvm进行分析。 - 查看内存的消耗状况。长期消耗,可以直接dump,然后MAT(内存分析工具)查看即可;短期消耗,图形界面情况下,可使用
jvisualvm的memory profiler或jprofiler;
8. 系统调优方法
评估现状 -> 设定目标 -> 尝试调优 -> 衡量调优 -> 细微调整 -> 设定目标
常见问题:
- 怎样降低Full GC的执行频率?
- 怎样降低Full GC的消耗时间?
- 怎样降低Full GC所造成的应用停顿时间?
- 怎样降低Minor GC执行频率?
- 怎样降低Minor GC消耗时间?
例如某系统的GC调优目标:降低Full GC执行频率的同时,尽可能降低minor GC的执行频率、消耗时间以及GC对应用造成的停顿时间。
检测工具
- 打印GC日志
-XX:+PrintGCDetails –XX:+PrintGCApplicationStoppedTime
-Xloggc: {文件名} -XX:+PrintGCTimeStamps - jmap
由于每个版本jvm的默认值可能会有改变,建议还是用jmap首先观察下目前每个代的内存大小、GC方式 - 运行状况监测工具
jstat、jvisualvm、sar、gclogviewer应收集的信息
- minor gc的执行频率;full gc的执行频率,每次GC耗时多少?
- 高峰期什么状况?
- minor gc回收的效果如何?survivor的消耗状况如何,每次有多少对象会进入老生代?
- full gc回收的效果如何?(简单的memory leak判断方法)
- 系统的
load、cpu消耗、qpsortps、响应时间
QPS每秒查询率:是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。在因特网上,作为域名服务器的机器性能经常用每秒查询率来衡量。对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。 TPS(Transaction Per Second):每秒钟系统能够处理的交易或事务的数量。 尝试调优:
注意Java RMI的定时GC触发机制,可通过:-XX:+DisableExplicitGC来禁止或通过 -Dsun.rmi.dgc.server.gcInterval=3600000来控制触发的时间。
##参考
http://blog.csdn.net/zjf280441589/article/details/53437703
https://www.cnblogs.com/daemonox/p/4419579.html
http://www.blogjava.net/jjshcc/archive/2014/03/05/410655.html